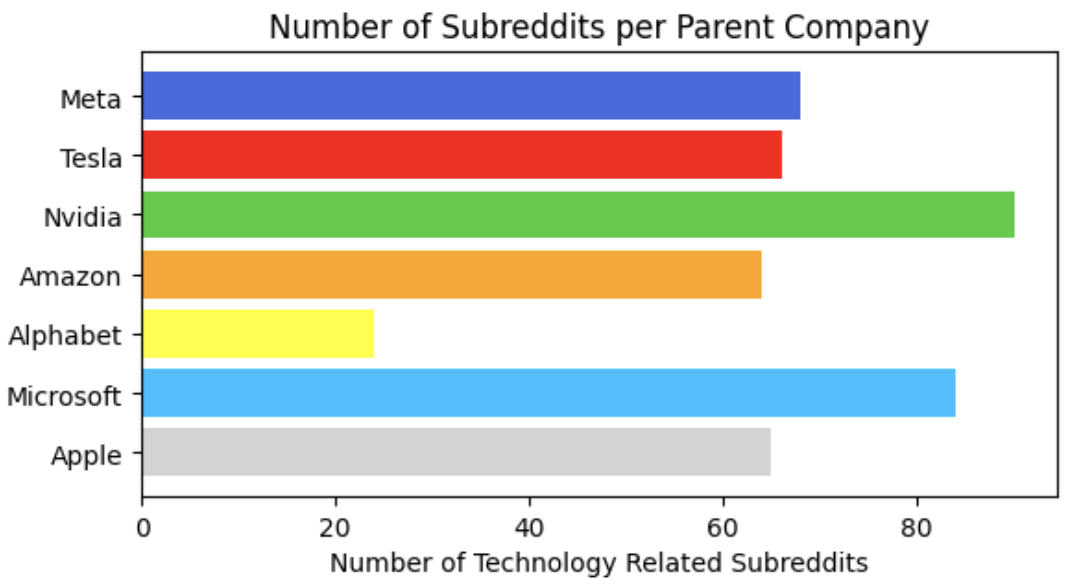
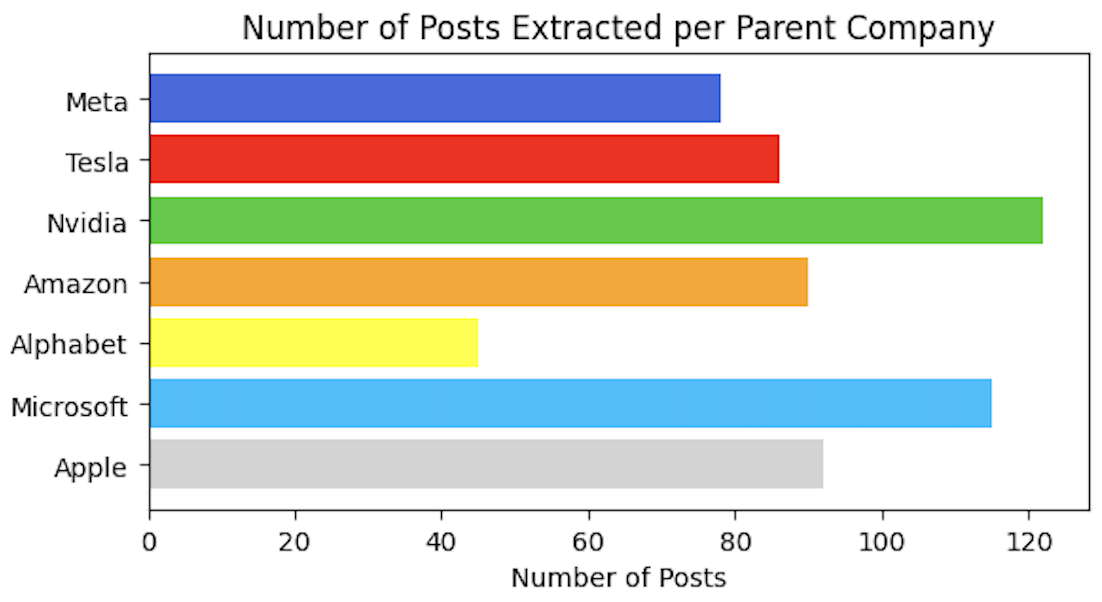
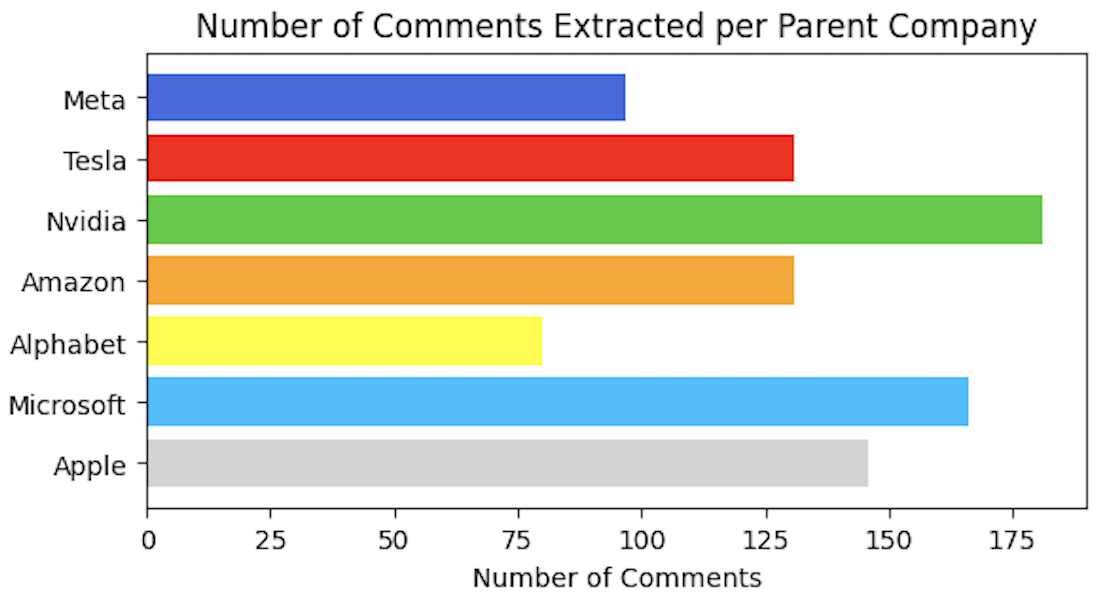
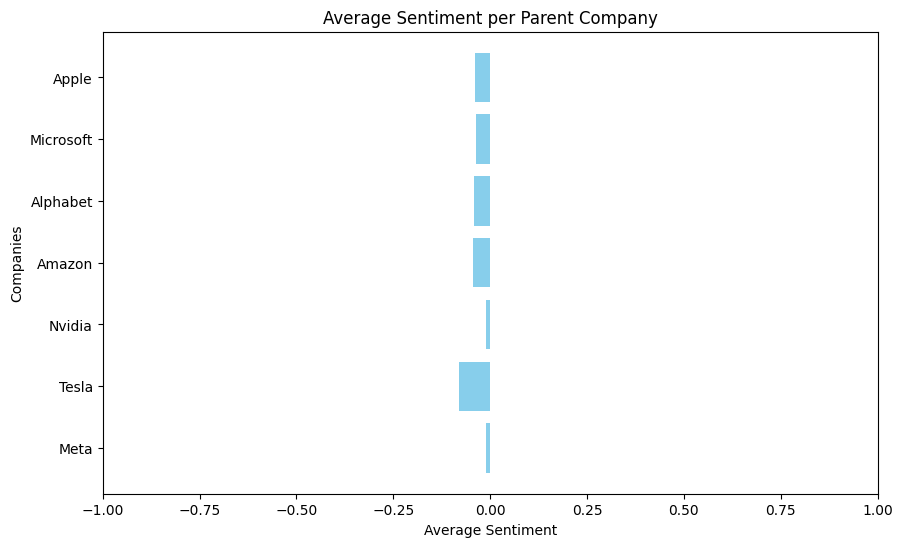
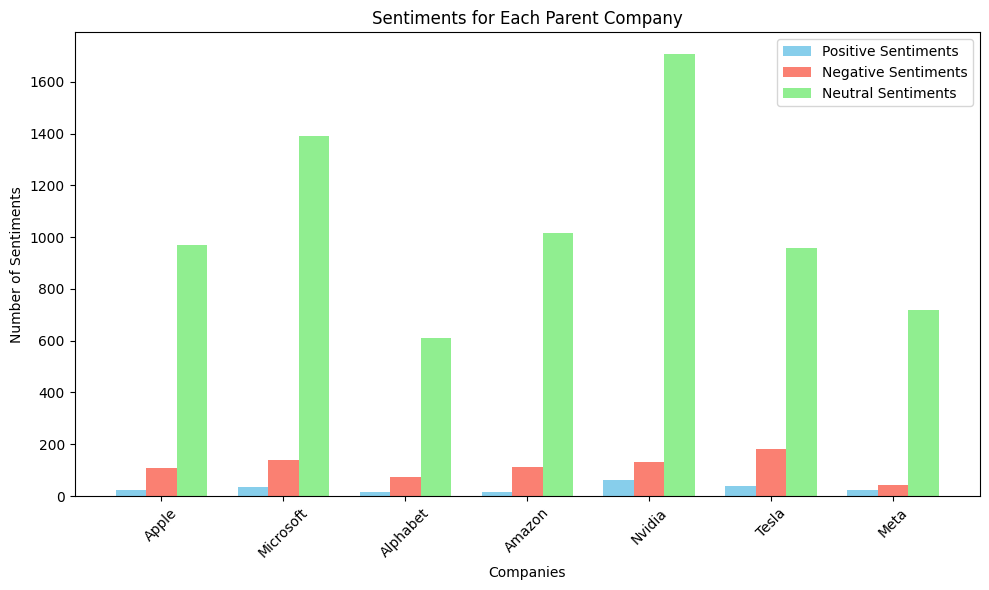
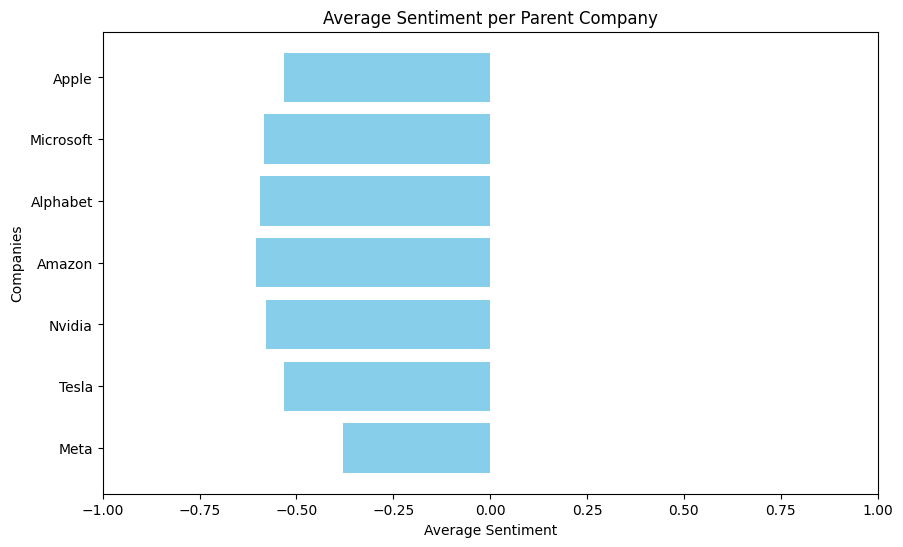
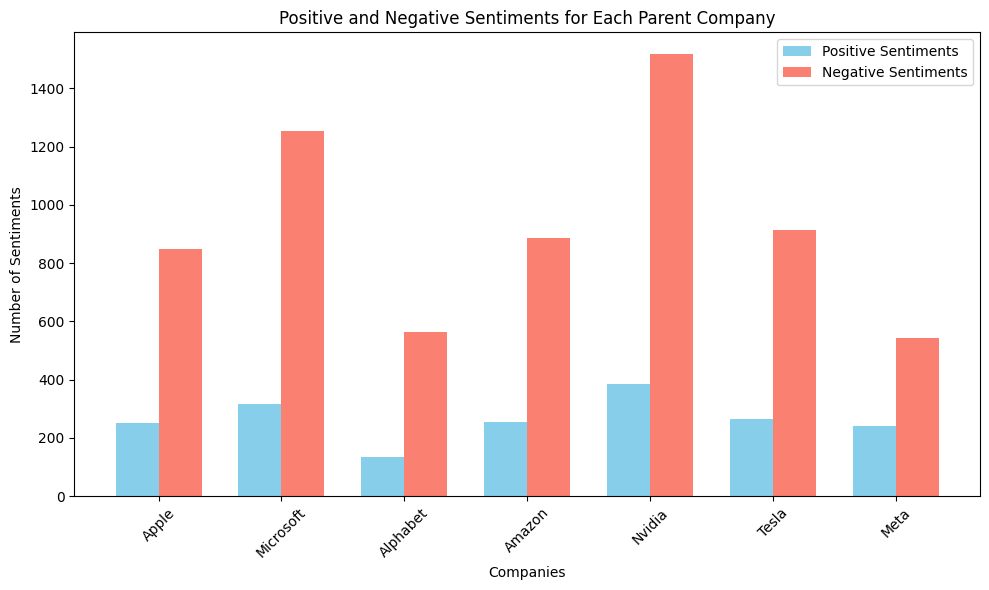
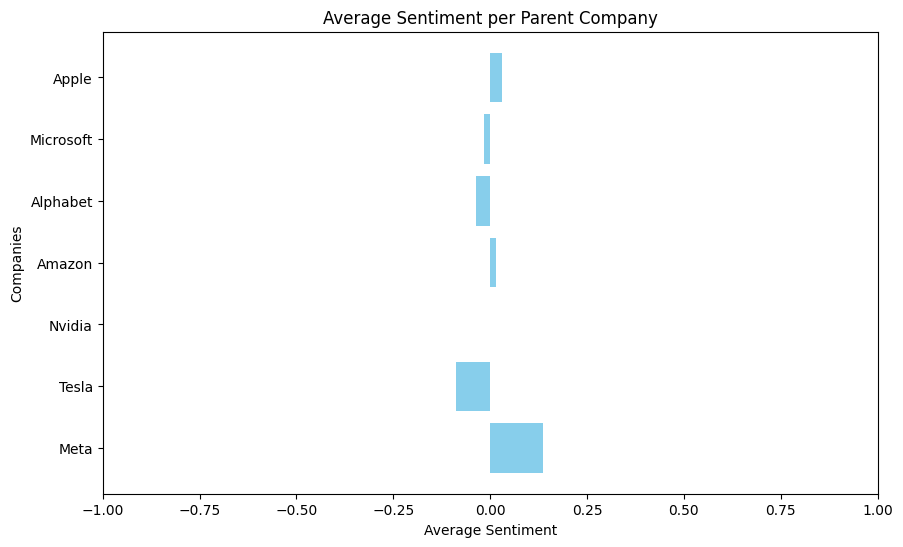
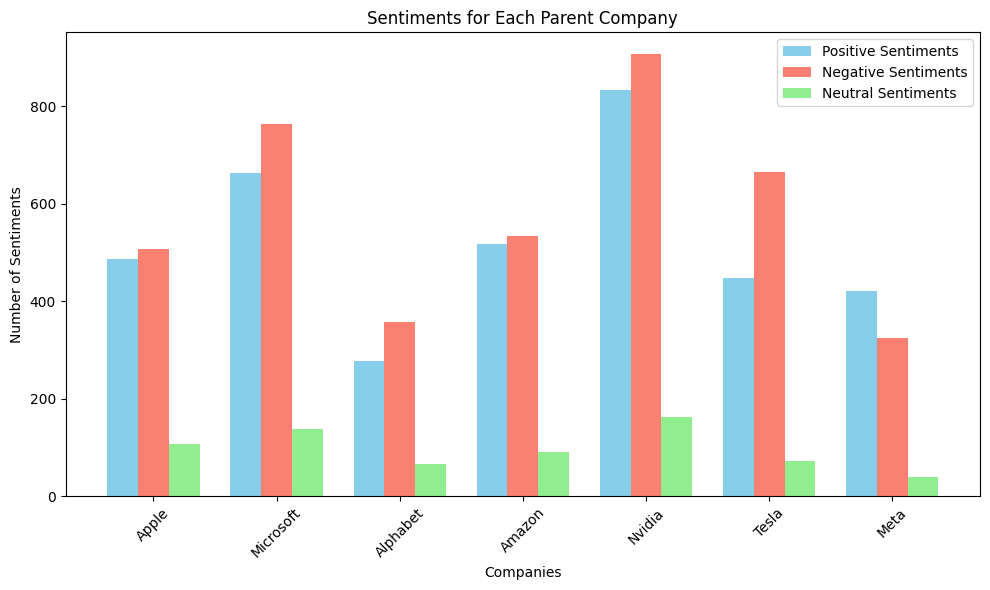
To recap, there are relevant subreddits for each parent company, a number of posts extracted for each subreddit, and a number of comments extracted for each post. In my sentiment calculation, I related the sentiment of each individual posts along with its comments in the following manner.
Firstly, text classification models often give you a a percentage score between 0 and 1 in the categories it is classifying under. So let's say a classification model is classifying whether a text is positive, negative, or neutral. It gives you a percentage score between 0 and 1 for each category, and the one with the highest percentage is often what you take as the guess of the model. For example, the statement "I love you" could have a positive sentiment score of 0.99, negative sentiment score of 0.01, and neutral sentiment score of 0.0. You would take the highest sentiment score as the classification for that text.
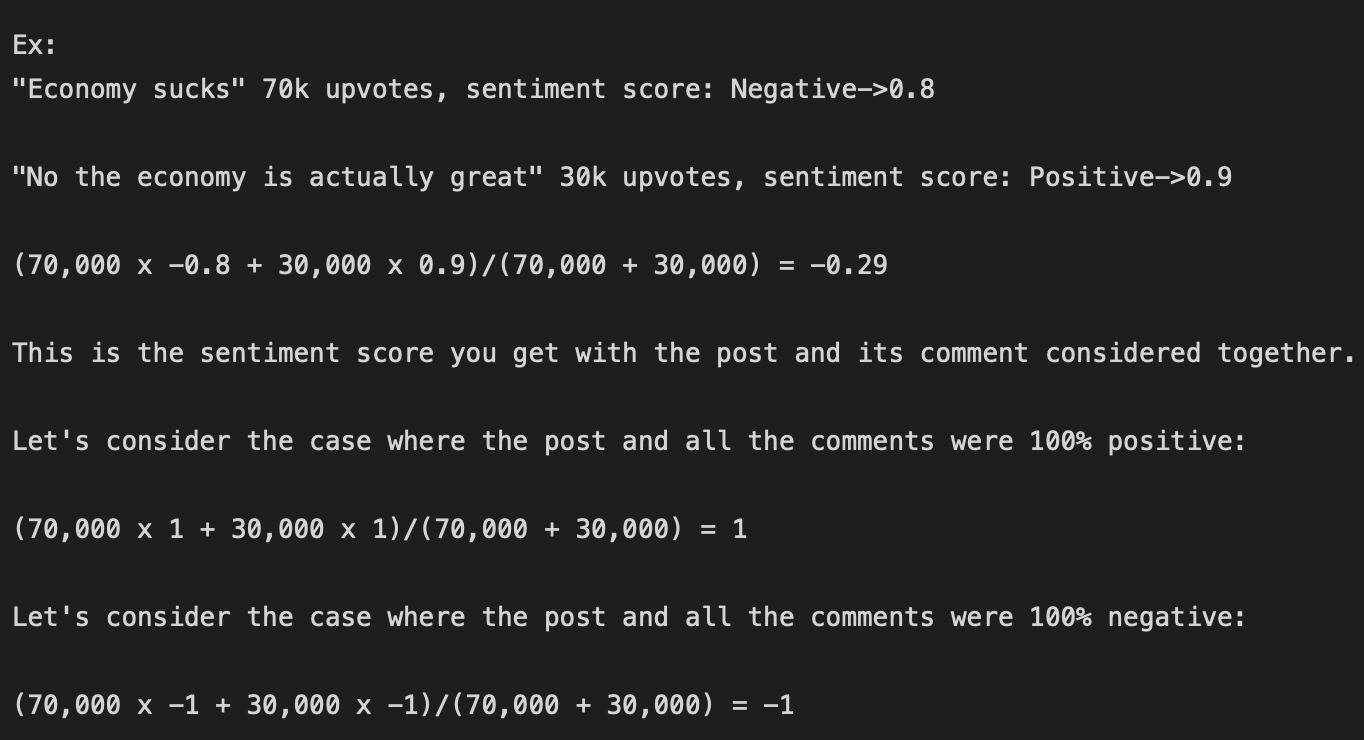
There is nuance in these scores. A post with 10,000 upvote ratio vs. a post with 100 upvote ratio should be included in the average sentiment accordingly. So for each post and comment group, I get a sentiment score for each entry. If the text is classified as positive, I take the sentiment percentage as a positive (+) number, whereas if its classified as negative, I take the sentiment percentage as a negative (-) number. If the text is classified as neutral, regardless of what the sentiment percentage is, I take the the score as zero (0). I multiply each sentiment score by the interactions (aka upvote ratio) for that entry, sum up these values for the posts and its comments, and divide it by the total interactions for the entries in that post/comment group. This gives a singular average sentiment score for that group.
The sign of the average score determines if that interaction was considered positive or negative, and its magnitude determines how postive/negative it was. Neutral scores don't contribute to the sentiment score, but the interactions on the neutral entry do. For example, if there is a post that has severe negative sentiment but a comment that is classified neutral gets a lot of upvotes, the average sentiment for that interaction might be in the negative direction but it's magnitude will be diminished by the amount of interactions the neutral entry received.